Train, tune & deploy energy-grade LLMs in seconds—not days
Seconds-level insight, audit-ready lineage and 50 % lower TCO — purpose-built for upstream, midstream and trading teams.
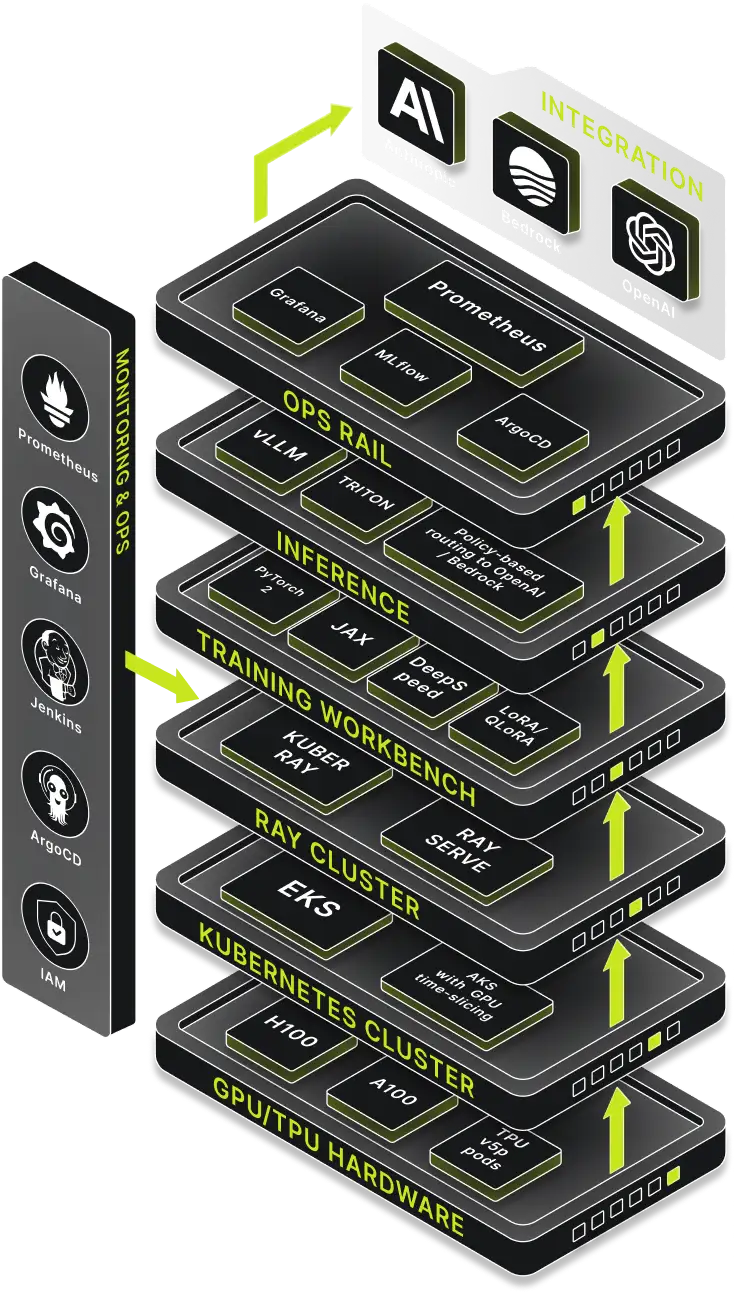
What Inside The Stack
| Layer | What it is | Why it matters |
|---|---|---|
| GPU/TPU Pools | Elastic H100, A100 & TPU v5p pods | Fastest silicon for seismic-scale pre-training and millisecond inference. |
| Kubertenes Fabric | EKS & AKS with GPU time-slicing | Auto-scales workloads, keeps utilisation > 70 %, no lock-in. |
| Ray Cluster | KubeRay + Ray Serve | One CLI flips a model from multi-node training to production endpoint. |
| Training Workbench | PyTorch 2, JAX, DeepSpeed, LoRA / QLoRA | 98 % of full fine-tune accuracy at one-tenth the GPU hours. |
| Interface Layer | vLLM, Triton, policy-based routing to OpenAI / Bedrock | Choose cheapest or smartest model per request—automatically. |
| OPS Rail | Prometheus, Grafana, MLflow, Argo CD | Live dashboards, one-click rollbacks, full lineage. |
Training & fine-tuning pipeline
Collect & curate
DDRs, LAS/SEG-Y, SCADA, ESG PDFs land in a Bronze Delta table, auto-tagged by well, field and timestamp
Tokenise & store
Domain-aware tokeniser preserves depths & API numbers; data sharded as JSONL in S3 / Blob / GCS.
Optimised fine-tuning
LoRA / QLoRA runs on 2 × A100s; 300 M tokens → 4 h; tracked in MLflow, promoted via Argo CD.
High-Throughput Inference & RAG
Vector DB options
7 B Llama-3-LoRA → P90 = 110 ms (Flash-Attention 2)
Smart routing
In-house model for daily ops, burst to GPT-4o when human-level nuance needed
Freshness
SCADA anomaly → embedded & searchable in 15 s; LLM always reasons on the latest pressure trend
Vector DB options
OpenSearch KNN or Pinecone PQ-IVF with metadata filters
Security & governance
Row-level IAM keeps regional data sovereign
SHA-256 lineage ties every prompt back to its source file
Azure OpenAI Private Link / Bedrock VPC endpoints—no data ever crosses the public internet.
Proven use-case snapshots
| Use case | What Winda delivers | Impact |
|---|---|---|
| Drilling optimisation | Real-time MWD + DDR analysis suggests BHA tweaks | ↑ ROP 2-5 %, fewer bit runs |
| Anomaly triage | Chat agent fuses SCADA spike + maintenance PDF → plain-English fix | 15 % ops efficiency lift |
| Regulatory reporting | Auto-fills OGMP 2.0 methane tables | Analyst hours ↓ 70 % |
| Knowledge mining | “Stuck-pipe at 14,500 ft in Wolfcamp A?” → cited SDR extracts | Decisions in minutes, not days |





Ready to see Winda on your own data?
Spin up a sandbox Ray cluster, ingest a week of well-test PDFs and start chatting with your domain-tuned LLM in under 48 hours.




